

Biochemistry in Perspective Series: Biochemistry and its Applications in Drug Development
Foreword
Biological organisms, such as humans and their individual cells, are incredibly complex and diverse systems. Nevertheless, certain unifying characteristics exist in all living things, from the simplest bacterium to the human being. The same types of biomolecules are present and they all use energy to function. These molecules are known as proteins, lipids, glycans, and nucleic acids. From the construction, modification, and interaction of these components, our cells develop and carry out specific functions. Biochemistry draws on a wide range of scientific disciplines to explore and study these molecules, cells, and functions. This has sequentially allowed us to gain a better understanding of the human body at the molecular level, which has led to more effective treatments in medicine. We will explore biochemistry in the context of this series, which examines the role it has played and will continue to play in our daily lives. In a nutshell, all life is the embodiment of biochemistry, and everything a living organism does is an expression of a biochemical process.
This Series is divided into six articles, including:
5. Biochemistry in Perspective Series: Biochemistry and its Applications in Drug Development
Biochemistry in Perspective Series: Biochemistry and its Applications in Drug Development
Biochemistry plays a fundamental role in understanding the molecular mechanisms that govern life and is essential in various scientific and medical disciplines. The drug discovery process involves multiple steps, including identifying compounds through screening compound collections using primary assays like high-throughput screening in vitro. Secondary assays, such as counter screens and ADMET studies, are also performed to assess absorption, distribution, metabolism, excretion, and toxicity. Structure-activity relationship (SAR) and in silico studies, along with cellular functional tests, are used iteratively to enhance the functional properties of the drug candidates. Through organic synthesis, new drug candidates with desired characteristics are synthesized [Figure 1]. Once a drug candidate successfully passes all preclinical tests, it proceeds to a clinical trial involving human patients. In order to speed up and enhance this process, researchers employ a wide range of tools and techniques.
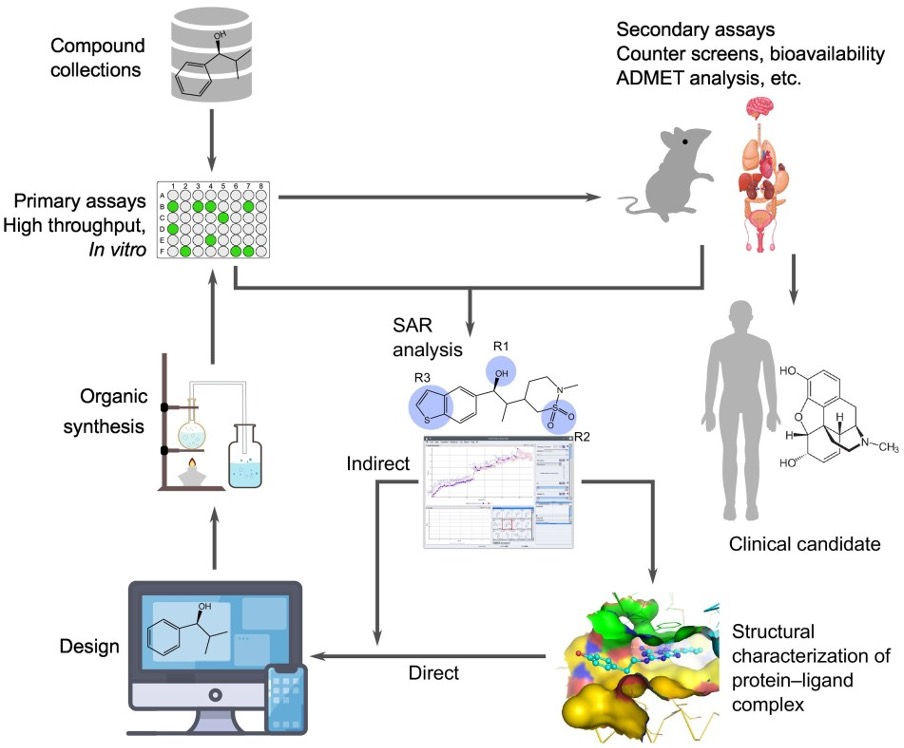
Introduction to Drug Discovery and Development
Many different stages and series of actions are involved in the drug discovery process. In general, it consists of four main stages: Early drug discovery, preclinical phase, clinical phase, and regulatory approval [Figure 2] (Berdigaliyev & Aljofan, 2020). The process of early drug discovery involves a multitude of collaborative activities and assessments, with the goal of identifying and enhancing potential drug candidates that target a specific objective. These candidates should positively impact a particular biological target associated with a disease, in order to develop effective treatments. The process entails multiple stages, such as target identification and validation, high throughput screening or high content screening, hit identification, assay development and screening, lead generation and optimization, and in vivo and in vitro assays. This phase employs a variety of laboratory techniques, including in silico tools, biochemical tests, cell cultures, and animal models (Hughes et al., 2011).
The second phase is the pre-clinical phase. Within this phase, the compounds identified during early drug discovery undergo refinement, optimization, and comprehensive laboratory and animal model testing. The primary objective is to accumulate substantial evidence of safety and efficacy prior to initiating clinical trials in humans. Additionally, this stage serves the purpose of determining the appropriate human testing doses. Furthermore, it is imperative to ensure that an adequate supply of the new compound is available before embarking on clinical trials. This entails adjusting production to meet the substantially increased demand during the clinical phase, as only small quantities were previously required (Berdigaliyev & Aljofan, 2020).

Regulatory authorities mandate preclinical studies as a prerequisite for advancing any investigational new drug application to the clinical phases. Clinical trials consist of four distinct phases: Phase I, II, III, and IV [Figure 3]. In the initial stage, the drug candidate's safety and tolerance are assessed in a small group of healthy subjects, typically ranging from 20 to 80 individuals. Phase I is geared towards how the human body absorbs, distributes, metabolizes, and excretes a drug, which is altogether referred to as Pharmacokinetics. This assessment is carried out by regularly drawing blood (typically from an inpatient setting) to monitor the drug's concentration in the blood plasma. Although an investigational drug has passed the preclinical phase of testing, phase I studies may still involve risks. Volunteer subjects are typically compensated for their time and effort in phase I studies, as there is usually little or no benefit to them (Meinert, 2006).
Subsequent to testing for tolerance and efficacy in a small group, phases IIa and IIb are initiated to evaluate effectiveness, tolerability, and dosages within a larger subject population. During this phase, the dosage form is developed. Phase IIa studies primarily focus on validating the therapeutic concept (proof of concept), while Phase IIb aims to identify the optimal dosage. These studies typically involve a range of 100 to 500 adult patients. In the final phase (phase II) before potential drug approval, physicians subject the drug to thousands of patients to confirm its efficacy and safety across diverse patient profiles. These studies also examine interactions with other medications. Typically, phase II and phase III studies are controlled studies, where some patients receive the new drug, and another group receives the existing standard treatment. Once an active substance successfully completes the clinical trials, data is collected and analyzed. Subsequently, it can be submitted for review to the appropriate regulatory authorities. The sale of a drug or vaccine necessitates approval from a national regulatory agency or a centralized process. Ultimately, out of the numerous compounds subjected to clinical study phases and regulatory scrutiny, only a single candidate secures approval as a drug or vaccine (Herrling, 2005; Meinert, 2006).
Phase IV studies, often referred to as post-marketing surveillance trials, occur subsequent to obtaining marketing authorization from regulatory agencies. They enable the collection of more extensive information pertaining to the efficacy and safety of the new drugs. A greater number of patients who are using the drug contribute to a wealth of data and allow for comparisons with existing treatments. The primary objective of these studies is to evaluate the drugs' long-term effects, facilitating the recording and prevention of adverse events (Meinert, 2006).

Regulatory Approval
The FDA, a federal agency within the United States Department of Health and Human Services, holds the responsibility for safeguarding and advancing public health. In pursuit of this mission, the FDA oversees the safety and effectiveness of all drugs. For the FDA to grant approval to a drug, it necessitates a comprehensive evaluation of the drug's efficacy and safety by the Center for Drug Evaluation and Research (CDER). Furthermore, the drug must demonstrate that its benefits outweigh any known or potential risks. The FDA's regulatory approval process adheres to a highly structured framework, encompassing the examination of the target condition and existing treatments, an evaluation of benefits and risks derived from clinical data, and the formulation of strategies for risk management [Figure 3].
Tools and Applications in Drug Discovery
Understanding Molecular Biology
Biochemistry delves into the structure and function of biomolecules, such as proteins, nucleic acids, lipids, and carbohydrates, that make up living organisms. This knowledge is fundamental in understanding the molecular basis of diseases and the targets for drug development. Understanding the three-dimensional structures of biomolecules, such as proteins and nucleic acids, is crucial in drug design. Techniques like X-ray crystallography, NMR spectroscopy, and cryogenic electron microscopy [Figure 4] help determine the structures of these molecules, aiding in the identification of potential drug targets and rational drug design. The examination of the triple helix's utility in drug design will be addressed in a later section of this article.

Drug Target Identification
A crucial element in crafting effective drugs is a comprehensive understanding of a disease's pathogenesis. When a biological target, for example a protein, can be targeted by a drug (therapeutic target), the biological target is referred to as "druggable", in other words, the therapeutic compound can effectively modify its biological activity (Sakharkar & Sakharkar, 2007). The search for potential targets often involves consulting existing databases and reviewing publicly available literature. Once a target is singled out, researchers proceed to validate its suitability for drug development before embarking on the screening process to unearth promising hits. Various techniques can be employed to identify a therapeutic molecule. Among the many strategies used to uncover these therapeutic compounds are high content screening (HCS), phenotypic screening, fragment-based screening, structure-based screening, and virtual screening (Blay et al., 2020; Kesh & Goel, 2023).
Drug Screening and Discovery
High throughput screening (HTS), often based on biochemical assays, enables researchers to test thousands of compounds for their potential to interact with specific drug targets. This process helps identify lead compounds with therapeutic potential. HTS was developed in the 1980s to automate and miniaturize biological assays using multi-well plates and robotic systems [Figure 5]. This allowed for the simultaneous testing of hundreds of thousands of molecules. Traditionally, drug discovery focused on targeting specific molecular disorders associated with diseases. This approach, known as target-based screening, involved testing molecules against a specific molecular target such as an enzyme or protein-receptor interaction (Yang et al., 2019). In contrast, phenotypic screening, including high-content screening, takes a broader approach by analyzing the final phenotype of cells rather than specific molecular interactions. HCS, developed in the 1990s, analyzes multiple cellular parameters such as cell viability, protein expression, and neurite outgrowth (a process wherein developing neurons produce new projections as they grow in response to guidance cues). By considering the overall effect of a molecule on cellular mechanisms, including compensatory mechanisms (which involve the movement of cerebrospinal fluid from the cranial vault towards the spinal cord), HCS is particularly valuable in complex and multifactorial diseases like neurodegenerative diseases and cancers (Li & Xia, 2019; Zock, 2009).

Protein Engineering
Protein engineering encompasses the design and creation of non-natural polypeptides, frequently achieved by altering amino acid sequences derived from natural sources. Contemporary methods permit the design of entirely synthetic protein structures and functions using computer-based techniques or through laboratory-directed evolution. Biochemistry plays a pivotal role in the realm of protein engineering, which entails the modification or creation of proteins tailored for specific drug-related purposes. This can involve the development of therapeutic antibodies, enzymes, or other proteins employed in various drug therapies. Techniques like DNA sequencing and mass spectrometry are used to identify and characterize genes, proteins, and their functions (Ulmer, 1983).
Computational Chemistry and Molecular Modeling
In the field of drug discovery, computational tools and software play a pivotal role by enabling the simulation and modeling of molecular interactions and the mechanisms of molecular recognition between proteins and inhibitors. Researchers harness these tools to design and anticipate how drug candidates will bind to target proteins, thereby enhancing their effectiveness and precision. This process involves optimizing the therapeutic compounds' ability to specifically interact with the intended targets, a critical step in the development of safer and more efficient therapeutic pharmaceuticals. Computational chemistry and molecular modeling contribute valuable insights into the design and screening of potential drug candidates, streamlining the drug development process and reducing the need for costly and time-consuming experimental trials (Cox & Gupta, 2022). Figure 6 below shows various parameters and applications utilized in computer-aided drug discovery.

Personalized Medicine
The practice of personalizing drug therapies through the biochemical profiling of individuals is revolutionizing medical treatment. This approach tailors medical decisions, interventions, and products to individual patients based on their unique genetic and metabolic characteristics, thereby optimizing the effectiveness of treatment regimens (Goetz & Schork, 2018) [Figure 7]. Often referred to as precision medicine, this innovative medical model stratifies individuals into different groups based on their predicted responses and disease risks. The terms personalized medicine, precision medicine, and stratified medicine are often used interchangeably to describe this concept, although some authors and organizations employ these expressions separately to convey specific differences.
Modern advances in personalized medicine leverage technology to unravel a patient's fundamental biology, including their DNA, RNA, and proteins, offering insights that confirm the presence of disease. For instance, cutting-edge techniques like genome sequencing can unveil DNA mutations linked to a spectrum of ailments, from cystic fibrosis to cancer. Another approach, known as RNA-seq, reveals the RNA molecules associated with particular diseases. Unlike DNA, RNA levels can change in response to the environment, providing a broader understanding of an individual's health status. Recent studies have established connections between genetic variations among individuals and variations in RNA expression, translation, and protein levels, underlining the immense potential of personalized medicine in transforming healthcare (Mathur & Sutton, 2017).

Bioinformatics
Bioinformatics is defined as the field dedicated to the analysis of biological data through the application of computer algorithms and statistical methodologies [Figure 8]. Its role in drug discovery and the life sciences is paramount, as it aids in pinpointing potential drug targets, scrutinizing gene expression patterns, and making comparisons between genetic variations in populations afflicted by diseases and those unaffected (Fernald et al., 2011). The utilization of bioinformatics not only assists in identifying promising drug targets but also plays a pivotal role in expediting drug development by providing insights into the molecular underpinnings of various diseases. Furthermore, it enables researchers to assess the impact of genetic variations on disease susceptibility, prognosis, and treatment responses, thus paving the way for more effective and personalized healthcare solutions. As the volume of biological data continues to grow exponentially, bioinformatics remains at the forefront of efforts to extract valuable knowledge from this wealth of information, ultimately advancing our understanding of complex biological systems and their role in health and disease (Overby & Tarczy-Hornoch, 2013).
These are only a few tools and applications listed that aid in drug development, and it is evident from this that biochemistry has a crucial role to play in this field, providing a foundation for understanding diseases at the molecular level and guiding the discovery and optimization of pharmaceutical compounds. Its applications extend across the entire drug development pipeline, from target identification to clinical trials, ultimately contributing to the advancement of medicine and the improvement of healthcare worldwide.

Biochemical Connections
Triple Helices in Drug Design
Triple-helical DNA was first observed in 1957 in the process of investigating synthetic polynucleotides. However, for many years, this phenomenon remained a mere subject of laboratory fascination. More recent investigations have unveiled that synthetic oligonucleotides, typically consisting of around 15 nucleotide residues, can adhere to specific sequences within naturally occurring double-helical DNA. These oligonucleotides are meticulously crafted through organic synthesis to match the precise base sequence required for specific binding. The third strand of the oligonucleotide snugly slots into the major groove of the double helix, establishing distinct hydrogen bonds [Figure 9].
Once the third strand is securely in position, it effectively barricades the major groove, making it impermeable to proteins that would typically attach themselves at precise locations, specifically proteins responsible for activating or suppressing gene expression within that DNA segment. This behavior hints at a potential in vivo function for triple helices, especially given the robust stability observed in hybrid triplexes where a short RNA strand bonds with a DNA double helix. Furthermore, in a different facet of this research, scientists investigating triple helices have developed oligonucleotides equipped with reactive sites strategically positioned within DNA sequences. These reactive sites can be employed to modify or cleave DNA at specific locations within a chosen sequence. This precision DNA manipulation is of paramount importance in the realms of recombinant DNA technology and genetic engineering (Shivanand & Noopur, 2010).

Numerous studies, both in cell cultures and in vitro solutions, have provided compelling evidence for the potential use of peptide nucleic acid (PNA) oligomers in modulating the transcription, replication, or repair of specific genes by interacting with DNA in various ways. They are small synthetic molecules that can specifically inhibit translation and/or transcription and have shown great promise as potential antisense/antigene drugs (Pooga et al., 2001). Additionally, researchers have documented a plethora of experiments showcasing the PNA oligomers' ability to function somewhat similarly to antisense RNA interference, thereby inhibiting gene expression at the translation stage. This effect has been observed in both cell cultures and, in a few instances, in studies involving mice. PNA achieves these outcomes by physically obstructing critical RNA-related processes (Pellestor & Paulasova, 2004).
In contrast, DNA or RNA oligomers employed in RNA interference rely on cellular enzymes to break down RNA-DNA or RNA-RNA duplexes they form. The RNA-PNA structure, due to its unconventional nature, does not benefit from such enzymatic assistance, as these enzymes are unable to recognize this foreign structure (Campbell et al., 2016). However, the distinctiveness of PNA oligomers also endows them with exceptional stability in biological environments. Enzymes responsible for breaking down other peptides do not recognize PNAs, granting them more time to encounter complementary RNA and hindering its function. In certain instances, obstructing an RNA process can lead to the restoration of a functional protein. In a notable example, Matthew Wood and his colleagues at the University of Oxford demonstrated in 2007 that PNA could exploit this effect. By injecting PNA into mice afflicted with muscular dystrophy, they observed an increase in the levels of the protein dystrophin, whose absence causes the disease (Yin et al., 2008). In muscular dystrophy, muscle mass is gradually lost and muscle strength is progressively weakened [Figure 10]. Muscular dystrophy occurs when abnormal genes or mutations interfere with the production of proteins necessary for muscle growth. The PNA effectively prevented a deleterious segment of the dystrophin gene from being translated into protein, eliminating a debilitating mutation while preserving enough functional dystrophin.

Both PNA oligomers and conventional nucleic acids encounter a common challenge concerning their limited bioavailability due to their large size and predominantly hydrophilic water-loving nature, which prevents their entry into cells protected by hydrophobic lipid membranes. Despite the remarkable stability of PNAs, they are swiftly excreted in urine owing to their hydrophilicity, with approximately half of the PNA in a mouse being eliminated in less than half an hour. Consequently, the realization of PNA-based drugs hinges on the development of appropriate chemical modifications or pharmaceutical formulations (combinations with other substances) to enhance PNA bioavailability. Indeed, the primary focus of research in genetic medicine revolves around overcoming the delivery challenge to reach cells within the body, as overcoming this hurdle is believed to be the final barrier preventing breakthroughs in the field of medical genetics (Pooga et al., 2001)
Membranes in Drug Delivery
The formation of lipid bilayers is primarily driven by the exclusion of water from the hydrophobic portion of lipids, rather than involving enzymatic processes, which allows for the creation of artificial membranes in a laboratory setting. Liposomes represent stable structures built around a lipid bilayer, forming spherical vesicles. These vesicles can be loaded with therapeutic agents internally and subsequently utilized for delivering these agents to specific target tissues. Each year, over a million Americans receive a diagnosis of skin cancer, often attributed to prolonged exposure to ultraviolet (UV) light. UV light inflicts damage on DNA in various ways, with one of the most common being the formation of dimers between two pyrimidine bases [Figure 11] (Vechtomova et al., 2021). Humans, a species with limited body hair and a habitual liking for sunlight, possess inadequate natural mechanisms to combat damaged DNA in their skin. Out of the 130 known human DNA-repair enzymes, only one system is specialized in repairing the primary DNA lesions caused by UV exposure (Vechtomova et al., 2021). In contrast, several lower species possess repair enzymes that we lack. Scientists have created a skin lotion designed to mitigate the consequences of UV light exposure. This lotion includes liposomes that are loaded with a DNA-repair enzyme obtained from a virus known as T4 endonuclease V. These liposomes effectively infiltrate the skin cells and, upon gaining entry, the enzymes traverse to the nucleus (Luze et al., 2020). There, they target pyrimidine dimers, initiating a DNA-repair process that can be finalized by the regular cellular mechanisms.

Catalytic Antibodies in Cocaine
Heroin and other addictive substances work by binding to specific receptors in neurons, mimicking the actions of neurotransmitters. To combat addiction, a common approach is to use a compound that blocks these receptors, preventing the drug from binding. However, addressing cocaine addiction presents a unique challenge. Cocaine inhibits dopamine reuptake, leading to an accumulation of dopamine in the system. This overstimulates neurons and triggers the brain's reward signals associated with addiction. Blocking receptors with a drug is ineffective for cocaine addiction and may worsen the situation by impeding dopamine removal (Yang et al., 1996). In the context of cocaine addiction, a specific type of enzyme known as an esterase can break down cocaine by hydrolyzing an ester bond in its structure [Figure 12]. This hydrolysis process induces a transitional state that alters the shape of cocaine. Scientists have engineered catalytic antibodies that target this transitional state during cocaine hydrolysis (Cashman et al., 2000). When these antibodies are administered to individuals struggling with cocaine addiction, they effectively break down cocaine into two harmless byproducts: benzoic acid and ecgonine methyl ester (Campbell et al., 2016). Once cocaine is degraded, it can no longer hinder dopamine reuptake, leading to a reduction in prolonged neuronal stimulation and a decrease in the addictive effects of the drug over time (Deng et al., 2002).

Advances in Cancer Treatment
There are many classical ways to combat cancer, most notably chemotherapy and radiation therapy. Both of these therapies are extremely hard on healthy cells and have severe side effects for patients. Another research field looking at ways to treat cancer involves targeting the mutated and non-functional p53 gene. The p53 gene stands as one of the most extensively researched tumor suppressor genes. Scientists have identified mutations or deletions of this gene in approximately half of all cancer cases. In the remaining half, where wild-type p53 is present, disruptions within the p53 signaling pathway and mechanism are often caused by abnormalities in the pathway. Given its pivotal role in preventing tumor development, p53 has garnered significant attention in the realm of drug development. Any effective therapeutic compound targeting the p53 pathway could potentially save countless lives (Duffy et al., 2014). Nonetheless, the design of therapeutics directed at this pathway has proven exceptionally difficult, despite over four decades of research in this field.
p53 is a transcription factor (a protein that is involved in the transcription and conversion of DNA to RNA), which is distributed in the cytoplasm and nucleus of the cell and binds to DNA regulating a diverse number of genes. The MBM2 and MDMX regulators normally maintain relatively low levels of the cellular p53 protein. These regulators promote p53 degradation through ubiquitination (protein modification through the attachment of a ubiquitin molecule). When cells are exposed to internal and external stress, such as DNA damage, hypoxia, nutrient deprivation, and cancer cell risk, they undergo a rapid increase in intracellular p53 protein levels. A critical component of this response is the activation of p53 as a tumor suppressor, which is crucial to the prevention of cancer. The accumulated p53 undergoes post-translational modifications, such as phosphorylation, acetylation, and methylation, which activate and stabilize the protein. Stabilized p53 proteins form tetramers in the nucleus, bind to target DNA, and regulate gene transcription, leading to changes in downstream signaling pathways (Wang et al., 2023). This ultimately helps initiate cell cycle arrest, DNA repair, and apoptosis, maintaining genomic integrity and preventing cancer (Duffy et al., 2014) [Figure 13]. Even though several signaling networks are controlled by p53, the exact function of p53 cannot be precisely explained by a simple and clear answer. There is no doubt, however, that p53 has a flexible and versatile response to environmental stimuli whether it is determining cell death or maintaining cellular homeostasis.

Conclusion
Drug development is a multidisciplinary and intricate endeavor that relies on the harmonious integration of scientific breakthroughs and meticulous research efforts. Biochemistry plays a crucial role in this, providing insights into disease mechanisms and the actions of potential therapeutic agents. By leveraging these insights, researchers can identify drug targets, understand signaling pathways, and evaluate the impact of candidate drugs on biological systems. This knowledge not only expedites the drug discovery journey but also guarantees the safety and effectiveness of novel pharmaceuticals.
As technology continues to advance and our understanding of biochemistry grows deeper, the future of drug development overflows with immense potential. The synergy between biology and chemistry is expected to lead to groundbreaking treatments that surpass current options for various diseases. This holds the potential to significantly improve the quality of life for individuals worldwide. In this ever-evolving landscape, the indispensable role of biochemistry in drug development remains at the heart of the pursuit of, longer, and more gratifying lives.
Bibliographical References
Berdigaliyev, N., & Aljofan, M. (2020). An overview of drug discovery and development. Future medicinal chemistry, 12(10), 939–947.
Blay, V., Tolani, B., Ho, S. P., & Arkin, M. R. (2020). High-throughput screening: today’s biochemical and cell-based approaches. Drug discovery today, 25(10), 1807–1821.
Campbell, M. K., Farrell, S. O., & McDougal, O. M. (2016). Biochemistry. Cengage Learning.
Cashman, J. R., Berkman, C. E., & Underiner, G. E. (2000). Catalytic antibodies that hydrolyze (−)-cocaine obtained by a high-throughput procedure. Journal of pharmacology and experimental therapeutics, 293(3), 952–961.
Cox, P. B., & Gupta, R. (2022). Contemporary computational applications and tools in drug discovery. ACS medicinal chemistry letters, 13(7), 1016–1029. https://doi.org/10.1021/acsmedchemlett.1c00662
Deng, S. X., de Prada, P., & Landry, D. W. (2002). Anticocaine catalytic antibodies. Journal of immunological methods, 269(1-2), 299–310.
Duffy, M. J., Synnott, N. C., McGowan, P. M., Crown, J., O’Connor, D., & Gallagher, W. M. (2014). p53 as a target for the treatment of cancer. Cancer treatment reviews, 40(10), 1153–1160.
Fernald, G. H., Capriotti, E., Daneshjou, R., Karczewski, K. J., & Altman, R. B. (2011). Bioinformatics challenges for personalized medicine. Bioinformatics, 27(13), 1741–1748. https://doi.org/10.1093/bioinformatics/btr295
Goetz, L. H., & Schork, N. J. (2018). Personalized medicine: motivation, challenges, and progress. Fertil steril, 109(6), 952–963. https://doi.org/10.1016/j.fertnstert.2018.05.006
Herrling, P. L. (2005). The drug discovery process. Imaging in drug discovery and early clinical trials, 1–14.
Hughes, J. P., Rees, S., Kalindjian, S. B., & Philpott, K. L. (2011). Principles of early drug discovery. British journal of pharmacology, 162(6), 1239–1249.
Kesh, M., & Goel, S. (2023). Target-Based Screening for Lead Discovery. In CADD and informatics in drug discovery (141–173). Springer.
Li, S., & Xia, M. (2019). Review of high-content screening applications in toxicology. Archives of toxicology, 93(12), 3387–3396. https://doi.org/10.1007/s00204-019-02593-5
Luze, H., Nischwitz, S. P., Zalaudek, I., Müllegger, R., & Kamolz, L. P. (2020). DNA repair enzymes in sunscreens and their impact on photoageing-A systematic review. Photodermatology, photoimmunology & photomedicone, 36(6), 424–432. https://doi.org/10.1111/phpp.12597
Mathur, S., & Sutton, J. (2017, Jul). Personalized medicine could transform healthcare. Biomedical reports, 7(1), 3–5. https://doi.org/10.3892/br.2017.922
Meinert, C. L. (2006). Clinical trials, overview. Wiley handbook of current and emerging drug therapies.
Neidle, S., & Sanderson, M. (2022). Principles of nucleic acid structure. Academic Press. https://doi.org/https://doi.org/10.1016/B978-0-12-819677-9.00003-2
Overby, C. L., & Tarczy-Hornoch, P. (2013, Jul 1). Personalized medicine: challenges and opportunities for translational bioinformatics. Personalized medicone, 10(5), 453–462. https://doi.org/10.2217/pme.13.30
Pellestor, F., & Paulasova, P. (2004, 2004/09/01). The peptide nucleic acids (PNAs), powerful tools for molecular genetics and cytogenetics. European Journal of Human Genetics, 12(9), 694–700. https://doi.org/10.1038/sj.ejhg.5201226
Pooga, M., Land, T., Bartfai, T., & Langel, U. (2001, Jun). PNA oligomers as tools for specific modulation of gene expression. Biomol Eng, 17(6), 183–192. https://doi.org/10.1016/s1389-0344(01)00075-2
Sakharkar, M., & Sakharkar, K. (2007, 07/01). Targetability of Human Disease Genes. Current drug discovery technologies, 4, 48–58. https://doi.org/10.2174/157016307781115494
Shivanand, P., & Noopur, S. (2010). Recombinant DNA technology and genetic engineering: a safe and effective meaning for production valuable biologicals. Int J Pharm Sci Rev Res, 1(1), 14–20.
Ulmer, K. M. (1983). Protein engineering. Science, 219(4585), 666–671.
Vechtomova, Y. L., Telegina, T. A., Buglak, A. A., & Kritsky, M. S. (2021). UV radiation in DNA damage and repair involving DNA-photolyases and cryptochromes. Biomedicines, 9(11). https://doi.org/10.3390/biomedicines9111564
Wang, H., Guo, M., Wei, H., & Chen, Y. (2023). Targeting p53 pathways: mechanisms, structures, and advances in therapy. Signal Transduction and Targeted Therapy, 8(1), 92. https://doi.org/10.1038/s41392-023-01347-1
Yang, G., Chun, J., Arakawa-Uramoto, H., Wang, X., Gawinowicz, M., Zhao, K., & Landry, D. (1996). Anti-cocaine catalytic antibodies: a synthetic approach to improved antibody diversity. Journal of the american chemical society, 118(25), 5881–5890.
Yang, X., Wang, Y., Byrne, R., Schneider, G., & Yang, S. (2019, 2019/09/25). Concepts of artificial intelligence for computer-assisted drug discovery. Chemical reviews, 119(18), 10520–10594. https://doi.org/10.1021/acs.chemrev.8b00728
Yin, H., Lu, Q., & Wood, M. (2008). Effective exon skipping and restoration of dystrophin expression by peptide nucleic acid antisense oligonucleotides in mdx mice. Molecular therapy, 16(1), 38–45.
Zock, J. M. (2009, Nov). Applications of high content screening in life science research. Combinatorial chemistry & high throughput screening, 12(9), 870–876. https://doi.org/10.2174/138620709789383277


Comments