

Morphology and the Form of Words
- Nicole Lorenzoni
- Dec 3, 2023
- 22 min read
Updated: Jan 13, 2024
For this introductory section, it suffices to preface that words compose the vast entity that is vocabulary, a dynamic realm subject to changes and evolution. Therefore, morphology engages with the dynamic processes shaping the vocabulary of a language. Objects of interest in the subfield of linguistics known as morphology, the study of words takes various integrated forms. Firstly, it entails the study of the forms words may take, extending to the internal structure of words. Governed by compositional rules specific to language systems, these rules dictate what speakers are allowed or not allowed to do with the provided vocabulary, determining the correctness of a word (Berruto, 2021).
Secondly, because vocabulary is not static, morphology studies the dynamics by which some words fall out of use and become obsolete along with the concepts they represent, while new vocabulary items arise as new notions, ideas, and objects emerge. For instance, the term selfie has recently entered the lexicon of several languages, reflecting the contemporary cultural phenomenon of taking self-portraits with a mobile device. On the other hand, terms like quill and typewriter, once commonplace, have become obsolete in everyday conversation, representing objects and fashions of bygone eras. Ultimately, morphology is concerned with how the vocabulary of a language is enriched through the introduction of new, often foreign, words into an established language system (Berruto & Cerruti, 2017).

The Definition of Word
As it was prefaced earlier, the minimal unit of study in morphology is the word. Words, as linguistic units, are integral to the linguistic competence of language users, contributing significantly to their knowledge and awareness of a language. Every language user possesses an intuitive idea or notion of what a word is—or, at the very least, they would be able to count the words within any given utterance in their language. Despite the intuitive immediacy with which language users conceptualize words, the precise definition of a word proves challenging for linguists. Unlike other more technical linguistic units, the word tends to resist precise delineation. For this reason, linguists often struggle to find common ground and reach an agreement on what a word truly is.
Graffi and Scalise (2002) reflect on the various difficulties that linguists may encounter in the attempt to define words, emphasizing that, like any other linguistic unit, a word can be considered from a variety of different perspectives. At the phonological level, words are not immediately separable because speakers do not typically take breaks between the enunciation of one word and the next; their formulations do not necessitate breathing breaks. Consequently, discerning individual words is not intuitive at the sound level. Another example of these challenges arises from the fact that the same concept, notion, or idea may not be expressed by the same number of words across languages. Differently put, because languages may employ different lexical and grammatical tools to convey the same idea, these ideas may not be translatable word-for-word across languages. A notable illustration of this difference lies in the contrast between languages that linguistically code articles and those that do not. For instance, Latin does not use articles, and the word puer, consisting of a single unit, corresponds to the boy in English, which is made up of two units. Russian is another notable example of a language that does not employ articles among its grammatical repertoire: the sentence Кот на столе (Kot na stole) means “the cat is on the table”, but it literally translates as "cat on table."

Another significant factor is the varying level of autonomy in word composition that languages afford their users. A notable illustration of this function is the comparison between French and German. German, characterized by a high level of compositionality, allows for the creation of very long words by juxtaposing multiple subcomponents. For instance, Freundschaftsbeziehungen is a single word in German, roughly translating to “demonstrations of friendship” in English. Its internal structure is analyzable into the following components: Freund (“friend”), Schaft (which in compound words it is a morpheme that is often used to form abstract nouns related to the base word), -s- (genitive marker, indicating an associational relationship between Freund and Schaft), Beziehung (“relationship”, “connection”), -en (plural marker). In order to convey the same meaning, other languages would often require a more complex phrasing, composed of more than one or two linguistic units.
An alternative perspective consists of resorting to the graphic dimension of languages by defining the word as any written element surrounded by two blank spaces. However, this solution faces its own set of challenges as well. For instance, it encounters difficulty when dealing with the unique forms of words in the Somali language, as exemplified by the word iskaashato, which conveys the concept of collaboration or working together. In Somali, words can exhibit complex and interconnected meanings that may not neatly fit into the conventional definition of a word separated by spaces. Conversely, certain Chinese words are intended to have a blank space as a component: ma ma means “Mum”. Additionally, the graphic definition falls short in accounting for the existence and nature of hyphenated words in English. While nouns like breakup, setup, and holdup can be written as single units, their hyphenated versions (break-up, set-up, hold-up) intentionally preserve a visual distinction between the components and are equally acceptable.
Building on the observation that the essence of a word is intuitively understood by language users, words can be defined as linguistic units whose form must not be altered by the introduction of external linguistic materials. The expression tu senti in Italian is made up of two words (“You feel”), a basic succession of subject and verb. This construction displays a certain degree of flexibility, as in Tu oggi non senti (“You cannot feel today”), where additional notions of negation and temporal reference are integrated. In contrast, the equivalent expression in Latin, sentis, cannot be broken up: if the speaker wished to add any other information, they would have to do so outside the word. This observation suggests a viable compromise in the pursuit of a satisfying and comprehensive definition for words. In conclusion, the intricate nature of linguistic coding is evident as languages encapsulate meaning in diverse ways. This variability is particularly pronounced when considering that some words or expressions may exist as a single entity in one language and as multiple words in another. Because languages exhibit the freedom to choose how concepts are physically attached or kept separate, the partitioning of meaning, be it grammatical or lexical, introduces a unique challenge—the absence of a one-to-one verbatim correspondence across languages. This dynamic interplay between linguistic form and meaning will be further unraveled and explored in the language typology chapter, shedding light on the variety of ways languages structure and convey information.

Lexis and Grammar
Before delving into the analysis of word composition, is it necessary to introduce a fundamental distinction that starts at meaning level and consequently stretches out to word forms and form composition. Depending on the type of meaning they carry, words and their components can fall into either one of two fundamental poles. First and foremost, meaning is essentially encyclopedic in its nature. On the one hand, it stands for concrete entities that are visible and testable through the senses, such as animals, objects, natural elements, and physical descriptions; on the other hand, it represents abstract notions not immediately accessible by sensory experience, such as sentiments and emotions, reasoning and logical thought processes, principles, and ideas. Words that carry encyclopedic meaning are called content words, because their purpose is to represent any reality in the real world that language users would be familiar with or have the potential to become familiar with. Encyclopedic meaning constitutes the lexical pole of any languages and it is coded via the following types of words: nouns, which represent object or ideas; verbs, which stand for actions or states; adjectives, which specialize in the descriptive function; adverbs, which specify manners of carrying out activities. On the other hand, there exist sets of words that do not have any particular encyclopaedic or world content, but their purpose is to relate content words between one another. They do not represent an existing entity in the world external to language, but explain how concepts relate to one another. For this reason, they are called function words, and collectively they constitute the grammar of languages. Prepositions do not have any content other than a relational one: on indicates the position on a surface or a specific date; articles introduce nouns (and in some languages, they share the same grammatical features as the nouns they accompany: German, for instance, employs the definite articles der, die, das and the indefinite articles ein, eine that not only convey the genders of masculine, feminine, and neuter, but also match the grammatical case and number of the associated nouns); conjunctions specify the logical connection between ideas (and expresses coordination, or expresses alternatives, but expresses contrast, and so on); pronouns are words that are used in place of nouns to avoid repetition and make sentences less cumbersome and endowed with a high degree of flow: in the utterance Yes, I know Mark. In fact, I’ve known him for years, the pronoun him is a substitute for the use of the proper noun Mark.

The lexical pole typically comprises a greater number of words than the grammatical categories within any given language. In simpler terms, lexical words outnumber grammatical words, which constitute a relatively restricted set. Furthermore, historical evolution of languages contributes to accentuate this discrepancy: as the language evolves, the lexical pole is subject to constant changes and linguistic enrichment, reflecting the developments in realities and entities that require communicative representation. As a result, the quantity of units belonging to lexical categories is not fixed or predetermined. In contrast, the number of units in grammatical categories, apart from being relatively smaller, undergoes changes less readily. When change does occur, it typically unfolds through an extended evolutionary process, such as the formation of future tense in English. This distinction leads to the characterization of these classes as open and closed, respectively. Open classes are receptive to new introductions and modifications, while closed classes are resistant to frequent alterations.
Linguistic categories, being a finite set, exhibit universality across languages. Although certain categories, such as nouns encompassing objects and verbs covering actions, seem nearly ubiquitous, it is essential to explore whether a word's content determines its categorical placement. On a broader scale, objects may align with nouns, and actions may align with verbs. However, within verbs, a sub-category, stative verbs, emerges as a commonality across languages. Stative verbs express inner states (to believe as in to believe in a deity), immutable facts (as represented by the verb to be describing unalterable qualities), or universally acknowledged truths. This semantics-driven perspective, while informative, encounters challenges in accounting for words unexpectedly placed in certain categories. An alternative approach grounded in the combinatory possibilities of words provides a more nuanced understanding of single categories. This method examines the linguistic regulations governing how specific categories combine with particular types of words. For instance, an article is identified by its ability to precede a noun. Therefore, distributional criteria offer a more effective description than semantic criteria alone.

Morphemes
Words are analyzable into smaller linguistic units called morphemes (Berruto & Cerruti, 2017). Each of these constituents carries meaning, whether lexical or grammatical. Notably, morphemes represent the smallest linguistic entities with the capacity to convey meaning. In contrast, linguistic units smaller than morphemes, such as phonemes and syllables, lack inherent meaning. The English term friendship, for example, is composed of two morphemes: the root morpheme, friend, which provides the fundamental concept of the word, and the suffix -ness, a grammatical marker that identifies the word as a noun. Although both elements are equally integral components of the word, they are invested with different functions. This interplay exemplifies the intricate nature of morphological composition and underscores the pivotal role of morphemes in shaping both lexical and grammatical dimensions of language. For instance, the term hurricane is a single word and a single morpheme, while the term cats is a word with two morphemes: cat, contributing the meaning of feline, and -s, serving as the English indication for a plural form. Cats’ is made up of one additional morpheme: the Saxon genitive apostrophe, signifying possession. On one hand, there can be no words without morphemes, as one is the minimal number of morphemes words can be made of. On the other hand, there is no theoretical limit to the number of constituents a word may contain. Contemporary German, as mentioned before, serves as a notable example of this, combining a high number of morphemes in the process of creating new words, resulting in lengthy and complex expressions.
Morphemes also possess the ability to be replicated, as they can be re-employed in a variety of words. Building upon the previously mentioned example of "friendship", friend can be utilized to create words such as "friendly", "friendliness", or "friendless", while -ship can find application in "dictatorship", "hardship", and "bipartisanship". Remarkably, both of these example morphemes maintain their functions across diverse linguistic contexts. However, there are instances of unique morphemes that appear in only one word and cannot be re-utilized in different contexts. For example, the morphemes cran and huckle solely exist in the words "cranberry" and "huckleberry", respectively. Lexical morphemes dictate the central meaning of a word, while grammatical morphemes provide information that contextualizes the utterance. Differently put, their meaning of lexical morphemes remains constant, regardless of the linguistic environment they appear in. On the other hand, grammatical morphemes expound how different parts of a sentence relate to each other, clarifying their conceptual and logical connections. As such, grammatical morphemes are firmly grounded in context (Berruto & Cerruti, 2017). From a learner’s perspective, lexis usually is something “memorized”, whereas grammar is “built according to rules” (Graffi & Scalise, 2002, p. 143): lexical morphemes are memorized in their given forms, whereas the process of utterance construction is carried out according to a set of indications that collectively constitute the grammar of languages.

An alternative approach to contrasting lexical morphemes and grammatical morphemes would be to conceptualize them as simple and complex words, respectively. Simple words are minimal units carrying meaning, and any further dissection will not result in morphologically independent and recognizable units. On the other hand, complex words are created through compositional processes and are complex entities–they can be subdivided into smaller components carrying meaning, whether lexical or grammatical. If more complex linguistic units are formed through compositional processes—either by juxtaposing smaller units to create a longer one or by inserting words into an extended sequence—one may naturally wonder about the boundaries of labeling. This prompts an exploration into which linguistic elements fall under the category of “memorized” and which are “constructed according to rules.” Having established that lexis represents content, its corresponding linguistic building blocks (morphemes and words) are typically memorized by language users. Phrases (further explored in the installment on grammar and syntax) represent the minimal unit constructed according to rules. The final step in construction is the complete utterance. These linguistic elements form a continuum as follows: morpheme > word > phrase > sentence. The parameter classifying linguistic units into these categories is their degree of complexity—specifically, their internal constitution or morphology, considering the contribution of each smaller component to the overall meaning.
Allomorphs
Every linguistic instantiation can be considered from two different perspectives: the theory and the practice, or the concept and its linguistic representation. Just as phonemes are theoretical entities and may possess a variety of instantiations depending on the context they appear in, the designations of the term morpheme are twofold: an abstract concept and the linguistic entity that functions as its linguistic representation. As a general tendency, a morpheme finds its actualization in one linguistic unity only. However, the alterations in form of a single morpheme are called allomorphs. Therefore, allomorphs are the different concretizations of the same idea of morpheme (Berruto, 2021). One representative example of allomorphs is the formation of opposite adjectives in Italian (although the same sound principles apply to English opposites), which is, in theory, expressed via the prefix in-. This prefix applies to most adjectives: something is inelegante if it is not elegant, inefficace if it is not effective, insufficiente if it is not sufficient or not enough. However, the morpheme in- changes its morphology according to the linguistic environment it is applied to: so it becomes il- in illegale, where the consonant sound l that opens the word legale (“legal”) exerts a phonetic influence on the prefix–a case of assimilation, as it was explored in the installment regarding phonetics; for the same reason, we say that something or someone is irrazionale (and not inrazionale) if they are irrational.
Free Morphemes and Bound Morphemes
Depending on whether they need to be attached to other linguistic material, morphemes are classified into free and bound. The former ones, as their name suggests, are autonomous: they can appear in isolation and they can be put in combination with other morphemes; when this is the case, they retain their linguistic independence–in other words, their meaning is in no way affected by other elements, and it is invariable regardless of the linguistic context they are featured in. The word man, for example, indicates an adult male human being, and it does so when it is used in isolation, as well as in complex words, such as gentleman, ungentlemanly, and one-man job. The latter are so called because their usage is strictly dependent on other morphemes: users may employ them only when certain other morphemes appear in utterances. A plural -s in English can only appear as a bound morpheme of nouns: it can never be used in isolation and it can never appear detached from a noun. On account of their dependency to be physically attached to other morphemes, bound morphemes are also called affixes, and “root” is defined as the word they need to be attached to.

While it may be tempting to equate grammatical morphemes to bound affixes and lexical morphemes to free affixes, this correspondence is more of a tendency rather than an unalterable rule. First of all, some bound affixes can be lexical in nature. One such affix is -ology in English, which is attached to the root to indicate its specific field of study. Therefore, biology is the study of living organisms, psychology is the study of the mind and behavior, geology is the study of the Earth's structure and composition. Affixes can also exert a derivational function instead of a grammatical one, when they serve the purpose of constructing new words based on the fundamental linguistic blocks provided. The English affix -er, for instance, is used to indicate a person or thing associated with the base word–the “doer” of the action. A writer is, literally, a person who writes; a teacher is a person who teaches; an actor is a person who acts–a word generated by the root word act and -or, the allomorph of -er. Furthermore, it's crucial to recognize the lack of a one-to-one correspondence between sets of bound and free morphemes when comparing different languages. Taking English and Italian as examples, a notable disparity exists between words like boy and their counterparts, such as ragazz- in Italian. While boy is a free morpheme capable of standing alone with a clear meaning, ragazz- is a lexical morpheme in Italian but is not as free in its standalone form. It requires an affix to be properly contextualized in utterances, aligning with grammatical parameters specific to Italian, such as gender and number (male or female; singular or plural). Having outlined the fundamental qualities of morphemes and affixes, the following section will delve into how these linguistic units are combined in sentences through processes such as flexion, derivation, and composition–which all result in the creation of new words.
Processes of Word Formation
Berruto & Cerruti (2017) recognize derivation and composition as the most important word formation processes. They also mention less productive processes such as conversion (also known as “zero derivation”),reduplication, and parasynthesis. Proceeding in the exploration of word formation processes, the focus will initially be on derivation and composition due to their primary significance. Subsequently, less productive processes will be addressed, including conversion, reduplication, and parasynthesis. The process of derivation involves the attachment of bound morphemes to other morphemes. These bound morphemes carry essential information of the grammatical type, providing indications related to number, genre, time, mood, voice, and the like.

Depending on where the affixes are physically attached to the other morpheme, derivation can be classified into the following types: 1. Prefixation: the affix (classified into prefix in this case) is attached at the beginning of the word. In Mandarin, the prefix 不 (bù) is used to indicate negation: therefore, if 好 (hǎo) means “good”, 不好 (bù hǎo) means “not good”.
2. Suffixation is the process whereby affixes are attached at the end of the stem. If an affix is to appear at the end of a word, it is called suffix. An example of suffix is the Turkish suffix -iyor, which is added to verbs to indicate the present continuous tense. By attaching -iyor to the verb yazmak (“to write”), the resulting form is yazıyor (“is writing”). Suffixes may also incorporate more than one bit of grammatical information. Romance languages offer a wealth of examples of this linguistic behavior: the Italian verbal conjugation system, for example, is founded on this characteristic. Therefore, due to the variety of grammatical information carried by the suffixes, the difference between the words concorderai (“you will agree”) and concordavano (“they used to agree”) is manifold: not only in tense (future and past, respectively), but also in number (second person singular and third person plural, respectively). English, for example, possess the following most productive suffixes, among others: -ly forms adverbs, indicating manner or quality (in words such as quickly, slowly); -ment forms nouns, indicating the result or action of a verb (development, adjustment); -ful forms adjectives, indicating full of or characterized by (helpful, joyful); -less forms adjective as well, but this time indicating a lack of something (fearless, endless); -ion is an alternative way of forming nouns, indicating an action or process (celebration, completion); the pair-able/-ible form adjectives specialized in the indication of the capability or possibility (readable, visible).
As an illustrative example, the words indubitably, unacceptable, and ungentlemanly, are analyzable into smaller components. In + dubit + -able + -ly: in negates or reverses the meaning; dubit serves as root, meaning “doubt”; -able makes the word an adjective, indicating the capability or possibility; -ly forms an adverb, indicating manner or quality. Un- + gentle + man + -ly: un- negates or reverses the meaning; gentle is a quality adjective; man is the root; -ly forms an adverb, indicating manner or quality. Un- + accept + -able: un- negates or reverses the meaning; accept is the root; -able makes the word an adjective, indicating the capability or possibility. It is worth noting that the process of prefixation does not tend to change the linguistic category of words (inelegant is an adjective just as elegant), while suffixation does: wintry is directly derived from the word winter, but the former is an adjective, while the latter is a noun. There are also languages that do not tend to attach morphemes together, but keep them distinct (as it will be explored more in depth in the installment pertaining to language typology). For example, the sentence He is a teacher, in Mandarin Chinese would be Tā shì lǎoshī, which literally translates as “He is teacher”, but the Vietnamese language isolates the components even further: the sentence Anh ấy là giáo viên breaks the word teacher into its two main components (teach- serving as the root, and -er, the suffix that indicates the doer of the action). So, the sentence is separable into its components in the following manner: anh is an honorific term used for older brothers, older male relatives, or any older male in general. It is also commonly used as a polite way to address or refer to someone; ấy is a demonstrative pronoun that adds emphasis or specificity. In this context, it is used to indicate a particular person. They combine to form the personal subject he. Là translates to "is”. Giáo means "teach" or "education.” Viên means "person" or "individual".

3. Infixation (which makes use of the affixes called infixes) places linguistic material within a root, breaking it up. One of the languages where infixation is a regular and natural part of the morphology is Tagalog, an Austronesian language spoken in the Philippines. The verb gawa (“to do/make”) becomes gumuwa (“to complete or finish making/doing”) via the addition of the infix -um-, which is used to indicate that the action of the verb is intentional, completed, or accomplished (also characterized by a vowel alternation: in the example illustrated, the vowel a changes to u as a consequence of the inclusion of the infix -um-. This vowel alternation is a phonological feature that enhances the flow and harmony of the word structure in Tagalog infixation). English makes use of infixation too (albeit much less than prefixation and suffixation): for example, in British English, the addition of the expletive infix bloody in the middle of adjectives results in playful and informal exclamations, as in fan-bloody-tastic.
4. Circumfixation makes use of a pair of affixes (in this instance, they are called circumfixes) and one member of this pair precedes the root, the other one follows it. One classic example for this is the German formation process for the past participle, which is sometimes formed via the circumfixes ge- and -t. Thus, gesagt means “said” (from sagen, “to say”), gebracht means “brought” (from bringen, “to bring”), and gemacht means “done/made” (from machen, “to do”). 5. Transfixation is a rare linguistic phenomenon whereby a set of morphemes is inserted within the root of a word. In this context, the term "transfix" is used to describe non-concatenative morphological processes. This process is especially productive in Afro-Asiatic languages, particularly in Semitic languages. For instance, in Arabic, the root k-t-b generally refers to the semantic field of writing. When this root is combined with specific transifx patterns, a set of grammatical features is incorporated to generate a new word: the expression kataba, for example, means “he wrote”; kitāb means “book”, and kātib means “writer” or “author”.
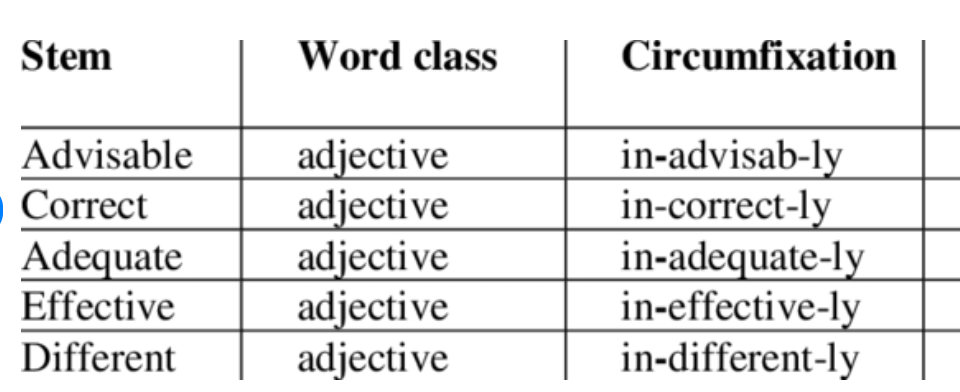
Composition is the way of forming brand new words by attaching together pre-extant words. This process differs from derivation in that derivation combines a free form and a bound form, whereas composition combines independent forms: counterpart is the result of the juxtaposition of the free morphemes counter and part. Compound words are classically classified into the following major types: endocentric, exocentric, and dvandva. In endocentric compounds, one of the elements functions as the central or core element, carrying the main semantic content, while the other element(s) serve to modify or specify the core element. The central element is called the “head” of the compound word. The entire compound word inherits linguistic information from its head, including category, syntax, meaning, and genre (in languages that feature this distinction, such as Romance languages). While identifying the head of a compound word can be challenging, the operation is relatively straightforward in English, where the head is traditionally the element on the right, as seen in examples like apron string, blackboard, overdose, rattlesnake, honeysweet, and icy cold. Exocentric compounds do not have a head, because the word as a whole does not inherit the meaning of any of its individual elements. The meaning must then be inferred from the combination, and none of the elements functions as the head or central element. The word redhead is an example of an exocentric compound because the hair color of the person is not directly specified by either red or head. The meaning is derived from the combination rather than any one element.
In linguistic constructions, a dvandva refers to the combination of two or more words to express a concept that is jointly described by each word. This structure is notably present in languages such as Hindi and Sanskrit. In a dvandva, the connected words maintain their individuality, and the resulting meaning is a connection between the concepts conveyed by each word. An exemplary instance of a dvandva in Sanskrit is rāma-lakṣmaṇau, which combines the names Rāma and Lakṣmaṇa to signify the two brothers Rāma and Lakṣmaṇa. Beyond dvandvas, various types of compound words exist across languages. One such type is incorporating compounds, exemplified in English by phrases like to babysit or to horseride, where a verb incorporates a noun into a complete expression. Syntagmatic compounds, such as a pipe and slipper husband, involve combining words in a sequence to convey a specific meaning. Reduplicated compounds and truncated compounds are additional linguistic phenomena that showcase the diverse ways in which languages create compound words, each with its unique structure and semantic nuances.

Conversion is a linguistic process that involves the transition of a word from one linguistic category to another over an extended period. This shift doesn't manifest as an outward linguistic change, leading to its alternative label of “zero derivation.” English, known for its productivity in this regard, frequently morphs nouns into verbs. An example of this phenomenon is the transformation of the noun Google into a verb, as it can be seen in the sentence I'll Google that information for you. Historically, English expressions for the future have followed a similar path of transitioning from one category to another. A prominent example is the word will, which originally functioned as a noun with the meaning of “volition” before evolving into a modal verb. Reduplication entails redoubling of one linguistic segment that results in the creation of a new linguistic item. In Hawaiian, for example, the adjective for “big” is nui; the reduplicated form, nui nui, means “very big”. Parasynthesis consists in the addition of a prefix and a suffix to a root word. In Japanese, for example, the adjective nemui means “sleepy”. The parasynthetic: nemuku naru (“to become sleepy”) results from the addition of -ku naru to the base form. It is also noteworthy that, in certain languages, word stress plays a crucial role, as explored in the previous installment. In English, for instance, it serves as a productive factor in distinguishing between nouns and verbs. Considering the word import, for example, when the stress is on the first syllable, it functions as a noun, while with stress on the second syllable, it becomes a verb.
In conclusion to the exploration of word formation processes, additional intriguing mechanisms that contribute to the dynamic evolution of language will now be briefly touched upon. Beyond the major word formation processes, languages exhibit creativity through procedures like blending, where disparate elements meld into innovative hybrids, such as smog from smoke and fog, or brunch, seamlessly merging breakfast and lunch, or the informal apericena in Italian, which fuses the words aperitivo (“aperitif”) and cena (“dinner”). Clipping, on the other hand, involves the deliberate omission of parts from existing words, be it the initial or final segments, resulting in creations like phone from telephone or telly from television. Back formation introduces a fascinating interplay between clipped forms and conversion, crafting new words by removing affixes, as seen in the formation of edit from editor or babysit from babysitter. Acronyms and initialisms harness the power of abbreviation, with examples ranging from OD for “overdose” to BBC for “British Broadcasting Corporation”, to DOA for the expression “dead on arrival”, each letter pronounced individually in the latter. Additionally, language growth extends to the formation of neologisms, either motivated by necessity or arising ex-nihilo, as speakers innovate with words like blog and Internet. Exploring further, reduplication presents a compelling method, utilizing total or partial repetition, as observed in forms like boo-boo. Borrowing from other languages emerges as another mode, where words are adopted due to necessity, domains, or prestige (which will be explored further in the following segment). The captivating phenomenon of etymology folklore involves the alteration of unfamiliar words to resemble more familiar ones, contributing to linguistic evolution. Shifting focus to semantic change, words undergo transformations such as generalization, specialization, metaphorical use, and semantic shift. For instance, liquor once denoted any liquid and meat referred to any food. Finally, the intricate tapestry of language growth includes the fascinating phenomenon of creating new roots or coining words, either through a motivated process or spontaneously from nothing.
Lexical Layers of Languages
Graffi & Scalise (2002) propose that the vocabularies of languages consist of central and peripheral layers. The “native” layer is situated at the core, and forms the foundational elements of a language. In contrast, the non-native layers, located at the peripheries, come to integrate the native layer over time, and can only emerge through interactions with other languages. Italian, for example, illustrates a language with numerous non-native layers. This is evident in its lexical entries, featuring a wealth of words of Greek origin, along with a significant number of foreign words. English, too, showcases the interplay between native and non-native layers, as seen in its doublets or double couplets. These are pairs of words that, despite having similar meanings today, have different historical origins. The words dark and obscure, for example, are both used to convey a lack of light, but dark has Old English origins, reflecting its native layer, and obscure has Latin roots, representing a non-native layer. Attesting to the rich historical and linguistic tapestry of English, each word contributes unique nuances to the language (both have secondary meanings: dark can also refer to the absence of light in terms of color, such as dark shades of a color, and obscure is metaphorically extended to describe something difficult to understand). In this way, the layers of a language, whether native or non-native, contribute to its lexical richness and complexity.
Words belonging to the non-native peripheries are mainly classified as loanwords and calques, depending on the extent to which they have been phonetically and morphologically adjusted to the characteristics of the recipient language. A loanword is a word directly taken from a source language and used in another without any outward alteration to its original qualities–that is to say, without translation. Therefore, loanwords retain their original form and meaning. For instance, the English word ballet is a loanword from the French language. The term is borrowed as is, with no attempt to translate it into an equivalent English term. Conversely, several English words have entered the lexicon of many languages, such as computer, weekend, OK. After a loanword has integrated into the vocabulary of a language other than its origin, it can either remain as a standalone term, identified as a loanword, or it can become productive, leading to the formation of derived words. In Swahili, for example, the word hotel has entered the lexicon as hoteli, and it has given rise to the derived expression hoteli ya kifahari (“luxury hotel”). A calque, alternatively labeled as semantic loan, occurs when a language adopts a phrase or morphological structure from another language, translating it literally. In essence, it involves a transposition of morphological or syntactic models from the source language into the receiving language. For example, the English term skyscraper is a calque of the French gratte-ciel, where each part of the word is translated literally; in Arabic, the word wristwatch has been imported as ساعة يد (sa'ah yad), whose literal translation is “hand hour"; in Mandarin Chinese, the calque 电脑 (diànnǎo), the word for “computer", literally means “electric brain".
Conclusion
Ultimately, delving into the realm of morphology illuminates its profound impact on shaping the fundamental structure of language. As a complex system overseeing the processes of word formation, morphology exposes the dynamic mechanisms that drive the evolution and adaptation of languages. The pivotal role of morphology in communicating meaning takes center stage, not only as a mirror reflecting cultural intricacies but also as a catalyst contributing to the rich tapestry of linguistic diversity across the globe.
Bibliographical References
Berruto, G. (2021). Che cos’è la linguistica. Bussole.
Berruto, G., & Cerruti, M. (2017). La linguistica. Un corso introduttivo (2nd ed.). UTET Università.
Graffi, G., & Scalise, S. (2002). Le lingue e il linguaggio. Introduzione alla linguistica. Il Mulino.
Haspelmath, M., & Sims, A. (2010). Understanding Morphology (2nd ed.). Routledge.
Lombardi Vallauri, E. (2014). La linguistica. In pratica. Il Mulino. Series: Itinerari.
Matthews, P. H. (1991). Morphology. Cambridge University Press.
Picello, R. (2018). Key Concepts of English Language and Linguistics: A coursebook for university students. Feltrinelli.
Visual Sources


This is a well-structured and insightful overview of the scope of morphology within linguistics. The focus on both the structural composition of words and the evolving nature of vocabulary highlights how language adapts to cultural and technological shifts. The examples of “selfie” versus “quill” effectively illustrate the dynamic interplay between linguistic form and societal relevance. It's also interesting how morphology intersects with historical and sociolinguistic factors, shedding light on language change over time. In academic work, especially in fields like linguistics, utilizing a Homework Writing Service can be helpful for managing such complex topics while ensuring clarity and proper structure.
I was struggling a lot with my assignments and understanding economic concepts felt really difficult. No matter how much I studied I couldn't get the results I wanted. Business Economics Assignment Help made a big difference in improving my knowledge and writing skills. Now I feel more confident in handling complex topics and my grades have improved. I am really happy with the support and guidance I received.
When it comes to assistance in assignment in Singapore,. the assignment help services offered by assignmenthelpsingapore.sg is the best in Singapore.
Assignmenthelp.co.za is the professional writing company providing assignment writing services to South African students in SA.
Connect with Student Life Saviour experts for best quality of assignment help services in all subjects worldwide.